IPFS - distributed web
IPFS⌗
Have you heard about decentralized storage? And how about decentralized hosting? In this post, we will introduce a project called InterPlanetary File System (IPFS) and show how to start using it to our advantage.

Introduction⌗
IPFS is an open-source internet peer-to-peer protocol that enables content sharing between users without the need of centralized servers. Some of you probably heard about such P2P applications, like BitTorrent, so the idea is not entirely novel. You can imagine IPFS as a combination of BitTorrent, Git and Hash tables.
The main difference between IPFS and traditional HTTP protocol is that files are not referenced by their location (url) but their content. Every version of the file has a unique hash so we can access the full history of the content.
Accessing files in the network is done via IPFS nodes that connect to each other and locate the desired content. Each node stores only content it is interested in plus some indexing information to figure out which node is storing what. You can either run such node locally or use a Gateway that translates your HTTP request into IPFS one in the background.
I will not deep dive into the technical implementation but you can check the official documentaion here.
IPFS vs HTTP⌗
Let’s see what kind of problems is this project aiming to solve. To do this, we can compare IPFS to the traditional HTTP protocol.
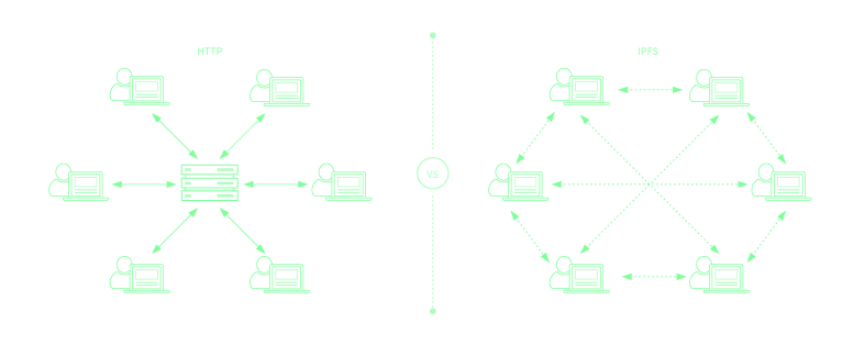
- Broken links - With HTTP, every file is referenced by a unique location (url). That means there must be a server that provides such file. When this file is deleted, moved or the server stops running, the url will be no longer valid. IPFS, on the other hand, will keep providing the content as long as there is at leat one node that stores its copy.
- Centralization - HTTP works with client-server architecture. Most data are stored in big datacenters like Google/Facebook. This raises concerns about data privacy, censorship etc. With IPFS, nodes are communicating directly, removing such middleman.
- Offline content - If server is not running, you are out of luck when trying to access your content. IPFS does not have such problem as long as there is at least one online node providing it.
- Effectivity and latency - Do you know the feeling when lots of people are watching the same stream or downloading the same software at the same time? It’s availability goes down if scalability is not sufficiently handled on the server side. Latency depends on the CDN (content distribution network). This problem is not present with IPFS since you are always connecting to the closest nodes that store your content.
IPNS and naming⌗
As we already mentioned, every file stored in IPFS has a unique hash which is used for its retrieval. Typical IPFS link looks as follows: ipfs/Qme2sLfe9ZMdiuWsEtajWMDzx6B7VbjzpSC2VWhtB6GoB1/wiki/Anasayfa.html.
However, changing the content of the file will also changes its hash and therefor its address. In most cases, we would like to access the latest version of our content on the same url. That’s what InterPlanetary Name Space (IPNS) is used for. It enables to assign a permanent name to each file and use it as a reference to the latest version of the content. This is done by asymmetric cryptography where the owner signs requested change using his private key.
Privacy⌗
Although it is true, that it is not easy to monitor hashes that has been added to the network, it does not mean such tools do not exist. So if you need to ensure that nobody else can access your content, you have several options:
- Running private IPFS cluster - You can run your own cluster without interacting with the public IPFS network (or specifying which content is propagated). That way, nobody else can access you data.
- Encryption - Simply store encrypted files on the public IPFS network. The content is safe as long as you have your encryption key.
- Gateways - Gateways might help when hiding your identify when requesting data from IPFS network. They have their own set of issues, though (might track your public IP address etc.).
How about data retention and deletion? Once you put something on the internet, it will haunt you forever - and it applies even more to decentralized software. You can delete any content from your local node and also request removal from other nodes in the network. But if someone decides to rehost the copy of your file, there is no way hot to remove it afterwards. This is similar to traditional web, where content can be re-hosted on different server. The main difference with IPFS is that you will be always able to find the copy.
Usecases⌗
In some scenarios, it might be more comfortable to use other, centralized solutions. There are couple of usecases that might benefit from using systems like IPFS drastically.
- Archiving - IPFS provides deduplication, high performance and decentrilize distribution even for huge datasets.
- Developing world - Due to the fact, that IPFS is not reliant on the existance of realiable backbone systems, it can provide data access even in regions where such infrastructure is lacking.
- Blockchains - Blockchains are immutable by design. Usually, referencing some content from transation metadata should be immutable as well, which is provided by IPFS by design.
- Service providing - Thanks to peer-to-peer content delivery, badnwidth cost for large data sets can be reduced.
How to begin?⌗
Cool, so now we see what kind of problems might IPFS help us with but what can I actually do to start using it? Let’s say we want to store some documents and don’t trust centralized servises like Dropbox or Google Drive. Or we want to run a webpage/blog without relying on traditional webhosting.
 IPFS Desktop
IPFS Desktop
- Terminal power lifting - If you are a power user comfrotable with the command line interface (CLI), you can simply read the docs.
- Running node with GUI - Running IPFS node locally is as easy as downloading IPFS desktop. This interface provides a user-friendly way of interracting with the network,
- Automated solutions - If you want to leverage some of the advantages of using IPFS, there are many solutions that automate the whole process. For example, if you need to host a web without needing to run local node, you can use services like Fleek that integrates with Gitlab and provides the whole CI/CD pipeline.
Bottom line⌗
This article was meant as a high level introduction into IPFS. If you are interested in learning more, the official documentation is very descriptive. By the way, this blog is deployed on IPFS using Fleek.